
Research Summary
What is the role of graphs in the Age of Foundation Models
Hello, this is Haitao, a final-year Ph.D. candidate at Michigan State University, I am actively seeking industry position starting around May 2025. My research interests include Graph Machine Learning, Recommender System, Large Language Model, and Information Retrieval. More Details can be found in my Resume, Research Statement, and Talk Slides. If you know of any relevant openings, I would greatly appreciate your consideration. Thank you! This article highlights my research contributions and offers an overview of my work.
Graphs describe complicated relationships between different instances, revealing how data instances are interconnected and uncovering collective patterns which are difficult to express with a single element. I have experienced many real-world graph usage, including relationships between cells in the tabular data, primary-foreign key connection in relational database, and how user behaviors are influenced by search engine result pages. However, due to the distinct graph characteristics in various domains, most existing solutions require careful domain-specific architecture designs and train from scratch on each application. It leads to an expertise-intensive process of graph modeling, hindering generalization across graphs from different domains with varying properties.
The era of Foundation Models (FMs) brings versatile model capabilities that reduce the requirement for training from scratch. FMs aim to recognize foundational patterns, enabling models to transfer knowledge across data from different domains and adapt to a wide range of tasks. In this context, two questions arises at the heart of my research: (1) Can graph have similar versatile models requiring less expertise designs? (2) Can graph enhance the utilization of existing foundation models in other modalities?
Revolving on this questions, my research are three folds:
- Academic focus: Towards Versatile Graph Models. Versatile Graph Models offer a general foundation, encapsulate complicated graph modeling details, and enable easy adaptation to benefit various downstream graph applications. A detailed research statement can be found here.
- Industry experience: Resource-efficient practical solutions via identifying and leveraging underlying relationships among data. Leveraging underlying relationship between instances to enhance machine learning efficiency with better data utilization and domain gap mitigation.
- Recent curiousity: LLM mechanism analysis to enhance output reliability. Despite impressive capabilities of LLMs, limitation can be found with superficial LLM responses. My research focuses on understanding this limitation and developing methods to achieve more reliable LLM outputs.
Academic focus: Towards Versatile Graph Models
Outline
- The failure of GNNs under distribution shift
- LLMs cannot solve graph tasks individually with incapability on capturing structure patterns
-
Develop versatile graph model via capturing essential network patterns
3.1 Essential structure patterns and underlying relationships
3.2 Versatile structural graph model from a generative perspective
3.3 When additional feature into consideration
- Align versatile graph models with LLMs for enhanced understanding on different modalities
1. The Failure of GNNs under distribution shift
- Problem statement: Tabular metadata tagging in Excel
- Metadata categorizes the role of each cell. A measure contains numerical data suitable for calculations like sum, count. A dimension contains categorical information that can be utilized for filtering and grouping.
- Tagging tabular metadata is a crucial preprocessing step for accurate operating on table fields, supporting advanced data analysis features in Microsoft Excel.
- Why GNN? Beyond the semantic meaning in each individual cell, there also exists underlying hierarchical and paratactic relationships between cells. GNNs are introduced to jointly capture both the semantic content in each cell and relationships among them.
- Challenge 1: Structural distribution shift. Given the flexibility and broad applicability of tabular data, their underlying graph structures can vary substantially, resulting in significant distribution shifts and performance degradation when GNNs are applied to new domains.
- Challenge 2: Data privacy. Tabular data from different organizations cannot be shared due to the data privacy policy.
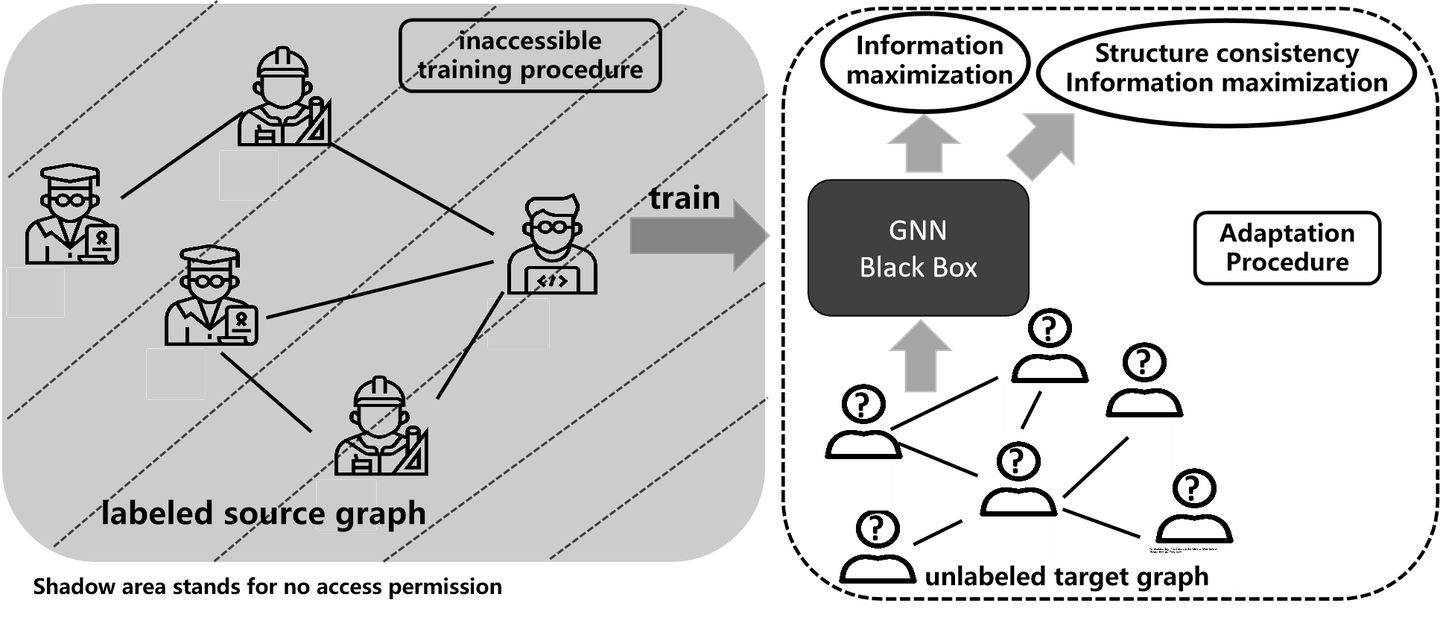
- New Scenario Definition: Source-free Graph Domain Adaptation. We adapt the source graph model to unlabeled target graphs without requiring access to the labeled source graph.
- Algorithm Solution: leveraging non-i.i.d. relationships between nodes in the target graph to adapt the initial discriminative ability from the source domain. Two structural proximity objectives are proposed to enhance prediction consistency.
- Usage: help to annnotate tag the tabular data
- Conclusion: GNNs are not robust across graphs with structural shifts.
My further research reveals that most GNNs struggle to capture (i) both homophily and heterophily patterns simultaneously and (ii) long-range dependency, such as PPR and Katz pattern. These observations motivate me to explore alternative solutions that could replace GNNs without above limitations. My first try is efficient MLP with graph regularization, but it fails after multiple tries.
[1] Source Free Graph Unsupervised Domain Adaptation, Haitao Mao et al. WSDM 2024 Best Paper Honor Mention
2. LLMs cannot be directly applied to solve complicated graph tasks
With the emergence of ChatGPT’s powerful yet largely unexplored capabilities(at that time), I started to wonder whether LLMs could effectively understand graph structures and potentially surspass GNNs.
Conclusion: while LLMs struggle to capture structural patterns effectively, they still offer valuable insights by understanding textual node features, thereby enhancing graph learning.
Detailed graph-LLM pipeline designs:
- LLM-as-Enhancer (Embedding Textual Node Attributes)
- provides a high-quality feature space that improves GNN performance.
- LLM-as-predictor (In-context Learning)
- transform both node attributes and structure information into text description
- Satisfactory zero-shot performance on node attributes alone.
- Adding structure may even degrade the performance
- LLM-as-annotator (a practical solution)
- LLMs can achieve satisfying zero-shot performance but incur high inference costs
- Select representative nodes for LLM to annnotation
- Utilize LLM predictions as pseudo-labels to train downstream GNNs.

[1] Exploring the potential of large language models (llms) in learning on graphs, Zhikai Chen, Haitao Mao et al., KDD Exploration 2024
[2] Label-free Node Classification on Graphs with Large Language Models (LLMs), Zhikai Chen, Haitao Mao et al., ICLR 2024
[3] Text-space Graph Foundation Models: A Comprehensive Benchmark and New Insights, Zhikai Chen, Haitao Mao et al., NeurIPS 2024 DB track
3. Develop versatile graph models via capturing essential network patterns
Since the success of LLMs cannot be directly applied to the graph domain, I pioneer the development of versatile Graph Models trained from scratch, capable of generalizing on new instances under distribution shift. To achieve this, (1) I endeavor to elucidate fundamental network patterns prevalent across diverse graphs and investigate their relationships through network science approaches, thereby achieving transferability across graphs. (2) I strive to design more versatile graph models which address the incapability of current GNNs in capturing these fundamental network patterns. The technical keys are three-folds: (1) collecting graph datas with diverse patterns (2) designing a flexible and expressive model architecture (3) establishing suitable training objective training
3.1 Essential structure patterns and underlying relationships
- Fundamental structural patterns
- Local Structural Proximity (LSP) corresponds to the similarity of immediate neighborhoods between two nodes.
- Global Structural Proximity (GSP) accounts for the ensemble of all paths between two nodes.
- Mathematical details: Design a latent space network model capturing both proximities. Proximity is described with distances in the latent space.
- Underlying relationships
- LSP proves to be more effective than GSP.
- GSP remains valuable when LSP information is absent.
- The failure of GNNs
- GNNs can capture LSP well while they struggle on graphs with GSP patterns
- the traditional Katz heuristic surpasses GNNs by 10% in a power network.

[1] Revisiting Link Prediction: A Data Perspective, Haitao Mao et al., ICLR 2024
3.2 Versatile structural graph model from a generative perspective
- Why GNNs fails?
- Data: Benchmark datasets only emphasizes LSP while GSP is largely ignored.
- Model: GNN architecture designs also focus on LSP.
- Objective: BPR loss requires carefuls design on negative samples while improper negative samples lead to learning incapability on capturing GSP patterns.
- Solution:
- Data: Pre-train over 100+ datasets across 33 domains, extending diverse datasets beyond commonly used graphs with limited patterns.
- Model: A graph diffusion model guided by multiple graph proximities, e.g., degree for LSP and network entropy for GSP, as guidance inputs.
- Objective: Generative objective inspired by network modeling literature
- Model usage
- Directly applicable learned representations for downstream tasks.
- Generate effective data augmentation, improving node classification, link prediction, and graph regression performance.
- Generates synthetic graphs with varied properties, allowing comprehensive GNN performance evaluation.

[1] Cross-Domain Graph Data Scaling: A Showcase with Diffusion Models, Haitao Mao et al., 2024
3.3 When additional feature into consideration
Beyond essential structural patterns common to all graphs, many graphs offer high-quality node features contributing additional knowledge.
- Feature proximity: nodes with similar attributes tend to be connected.
- Relationship with structure patterns: FP and LSP works on different instances, offering complementary effects.
- Inspiration: leveraging feature patterns to enhance graph modeling.
[1] Revisiting Link Prediction: A Data Perspective, Haitao Mao et al., ICLR 2024
3.4. Essential Feature patterns and underlying relationships
- Fundamental structural patterns: Homophily and heterophily patterns describe the tendencies of neighboring nodes to exhibit similar or dissimilar features
- Phenomenon: Real-world networks often exhibit both homophily and heterophily patterns
- Mathematical details: A variant of CSBM model to capture both patterns by assigning edges that reflect intra-group similarity and inter-group diversity.
- Underlying relationships through mean aggregation
- For homophily patterns, node features remain unchanged (i.e., red features stay red).
- For heterophily patterns, node features flip (i.e., red and green features switch).
- The symmetries on homophily and heterophily patterns differ through mean aggregation
- The failure of GNN: GNN can work on either homophily or heterophily, but underperform on the other side

[1] Demystifying Structural Disparity in Graph Neural Networks: Can One Size Fit All?, Haitao Mao et al., NeurIPS 2023
3.5. Feature-centric versatile graph model
- Why GNN fails? GNNs with fixed aggregation contraint their ability to handle both homophily and heterophily patterns effectively.
- Solution:
- Model: Transformer with adaptive neighbor selection
- Data: Improve feature quality which reduces the previous reliance on structure patterns
- Train: large-scale pre-training over 100 million sequences generated from random walk.
- Results:
- Selective Attention Mechanism with high weights on useful neighbor nodes
- Satisfied few-shot performance comparable with full supervised learning

[1] A Pure Transformer Pretraining Framework on Text-attributed Graphs, Yu Song, Haitao Mao et al., 2024
3.6. Align vesatile graph models with LLMs for enhanced understanding on different modalities
Many real-world tasks require comprehensive understanding on different modalities, necessitating the integration of graph knowledge with foundation models from other data modalities. Real-world scenarios I’ve encountered include:
- Conversational Recommendation requires understanding both textual user queries and prior interactions between users and items, often modeled as a user-item bipartite graph.
- Code Generation & Prograph Optimization requires an integrated understanding of code text, environment configurations and the underlying program logic represented as graphs, e.g., control flow graph, data flow graph.
Challenges on alignment
- No natural alignment. Unlike images, which can often be described easily with text, graphs lack straightforward textual descriptions due to their inherent flexibility and ambiguity. Consequently,the superioty of CLIP, which aligns image and text data effectively, can not extend to achieve similar success in the graph domain.
- Massive graph vocabulary. Taking recommendation scenarios as an example, each user and item has a unique identifier, leading to a vocabulary size in the billions. Aligning these identifiers with LLMs is challenging, as if is nearly impossible to effectively incorporating them into the LLM’s vocabulary.
To address these issues, I am currently working on quantizing graph knowledge into semantic identifiers, which could help bridge these gaps. I look forward to sharing more on this approach after the paper comes out.
Industry experience: Resource-efficient practical solutions via identifying and leveraging underlying relationships among data
My research maintains industry connections through internships at Microsoft, Snap, and Baidu, along with collaborations with Amazon, Google, Intel, and JP Morgan. My industry mentors have shifted my perspective from technique-driven to a problem-driven approach, highlighting real-world resource-efficiency challenges, including limited data availability, parameter budgets, and computational resources. My internship projects focus on identifying and leveraging underlying relationships to solve practical problems efficiently. Roughly speaking, the underlying relationships (graph structure) can help:
- Better Performance when labels vary smoothly over the high-quality underlying graph structure
- Better Data Utilization: Enabling semi-supervised learning and missing value imputation via capturing the relationship between instances.
- Domain Gap Mitigation via utilizing structural dependency between different domains.
Outline
- Search: Text-rich Unbiased Learning to Rank in Baidu
-
2.1. Multiple-locale Multilingual Session Recommendation in Amazon
2.2. Cross-domain Sequential Recommendation with Generative Retrieval
- Tabular Metadata Tagging in Microsoft
- Accelerate and Stabilize Neural Network training through insights on inter-neuron relationship
1. Search: Test-rich Unbiased Learning to Rank in Baidu
- Problem statement: Unbiased Learning to Rank (ULTR)
- Cost-effective click data: User click behavior data serves as a cost-effective alternative to expert annotation, providing a scalable approach to collect updated trends without requiring labor-intensive annotation processes.
- Biases in click data: User click behavior is inherently biased on the search result page presentation (SERP), for example, users favor clicking documents displayed in higher-ranked positions.
- The purpose of ULTR algorithm: ULTR algorithms aim to mitigate these biases, enabling the use of implicit user feedback for more accurate and unbiased ranking outcomes.
- Issue: Out-dated academic datasets (take Yahoo! learning-to-rank challenge dataset as an example)
- Limited SERP Features and User Behaviors: Only position-based features for SERP feature and click behavior are collected, which has led most ULTR algorithms to center their efforts around position-related bias along.
- Outdated query-document relevance features lack incorporation of recent advancements in NLP, limiting their effectiveness for developing ranking algorithms that leverage enhanced semantic understanding for real-world applications.
- New collected Baidu-ULTR dataset
- Comprehensive SERP feature and User Behaviors enables an in-depth analysis of multiple display biases.
- Updated Relevance Features utilizes MonoBERT to encode relevance features, enjoying the advanced language modeling techniques for enhanced semantic understanding.
- New challenges in the Baidu-ULTR dataset: Existing ULTR algorithms that primarily address position bias show no improvement over models trained directly on click data alone.
- Solution: an ULTR algorithm that considering biases from the entire search page presentation
- Suitable User Behavior Model Design
- Challenge: Many user behavior models are heavily position-focused and do not generalize to other SERP features.
- Graph model: Represent relationships between user behavior and various SERP features using a directed graph, enabling to describe the user behavior model flexibly.
- Graph Structure Learning to capture biases from diverse SERP features in a data-driven approach, adapting to the unique characteristics of each feature.
- Unbiased Learning Algorithm: Implement an algorithm to mitigate confounding biases by applying importance reweighting to the learned user behavior model.
- Suitable User Behavior Model Design

[1] A Large Scale Search Dataset for Unbiased Learning to Rank, Haitao Mao et al., NeurIPS 2022
[2] Whole Page Unbiased Learning to Rank, Haitao Mao et al., WebConference 2024
2. Recommendation
2.1 Multiple-locale Multilingual Session Recommendation in Amazon
- Problem Statement: Session Recommendation aims to predict next item the user would interact with based on previous item interactions in a single anonymous session
- Out-dated academic datasets:
- Limited text-attributes: Existing session recommendation datasets often lacks textual descriptions, which already shows great usages in recommendation including (1) address cold-start issue and facilitate cross-domain transfer (2) Generative Retrieval with semantic id (3) Conversational recommendation with LLMs.
- Small item set lacks of real-world item diversity. Moreover, efficiency challenges are also overlooked while many algorithms train with cross-entropy loss across entire item set which is computationally intensive and impractical for real-world large item sets.
- New collected Amazon-2M Session Recommendation dataset
- 100 times larger item set with multiple locale diversity
- Rich Multilingual Text Attributes enables exploration of cross-lingual and cross-regional transferability, transferring knowledge from large locales to facilitate the recommendation for underrepresented locales.
[1] Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation, Haitao Mao et al., NeurIPS 2023
2.2. Cross-domain Sequential Recommendation with Generative Retrieval
Ongoing project explores a novel approach for cross-domain recommendation by leveraging graph relationships. I’m excited to share more details once the paper is released early next year.
4. Accelerate and Stabilize Neural Network training through insights on neuron relationship
Neural networks, with their vast parameter scale, often suffer from slow and potentially unstable training. Reducing training resource requirements remains a key practical challenge. During my internship at Microsoft, I introduced a novel perspective centered on individual neurons, inspired by the insight that permutations of hidden neurons within the same layer leave the input-output mapping unchanged. By treating each neuron as a fundamental unit of analysis, I modified neuron-specific behaviors to improve both training efficiency and stability.

Neuron Campaign Strategy for Accelerating training procedure
- Goal: An initialization can promote model convergence, instead of only preventing training failure, e.g., gradient vanishing or explosion.
- Neuron Campaign Strategy: initiate a model with primary discriminative ability
- Create a large candidate neuron set utilizing traditional initialization strategies like Xavier
- Select neurons initialized with primary discriminative ability
- Combine winning neurons as the neural network initialization.
Stablize Neuron Response with better generalization
- Analysis: neuron with similar responses to instances of the same class leads to better generalization
- Solution: Regularization term to minimize intra-class variance in neuron responses, thereby stabilizing neuron activation patterns.
- Results: promotes a more stable training process, leading to faster convergence and improved generalization across tasks.
[1] Neuron Campaign for Initialization Guided by Information Bottleneck Theory, Haitao Mao et al., CIKM 2021 Best Paper Award
[2] Neuron with Steady Response Leads to Better Generalization, Haitao Mao et al., NeurIPS 2022
LLM Mechanism Analysis for more reliable LLM outputs
ICL Mechanism Analysis
- In Context Learning (ICL) serves as a fundamental emerging capacity, underpinning a wide range of complicated abilities.
- ICL learns from a few prompt examples, enabling downstream generalization without requiring gradient updates
- Mystery on how ICL achieves successes:
- Unexplainable Phenomenon: sensitivity to the ICL sample order, robust to wrong input-label mapping
- Unclear origin of ICL ability: Influence by pre-training data qualities, model-scale and task difficulties
- Core question: Can LLMs really learn new skills from ICL examples?
- Key analysis approach through the lens of data generation functions
- Skill is formulated as data generation function
- Skill recognition refers to the ICL mechanism which selects one learned data generation function previously seen during pretraining
- Skill learning refers to the ICL mechanism which can learn new data generation functions from ICL examples distinguished by whether LLMs can learn a new data generation function in context.
- Suitable Data generation functions enables
- Theoretical Analysis with mathematical modeling with HMM, LDA, and other functions in the NLP domain
- *Controllable empiricial analysis on synthetic data generated by different functions
[1] A Data Generation Perspective to the Mechanism of In-Context Learning, Haitao Mao et al., 2024
Convergence guarantee on iteratively applying intrinsic self-correction
- Intrinsic self-correction ability: LLMs can improve their responses when instructed with only the task’s goal without specific details about potential issues in the response
- Example Instruction: “Please ensure that your answer is unbiased and does not rely on stereotypes”
- Advantage: efficient than other methods necessitating feedback from humans, tools, or more powerful LLMs.
- Challenge: Intrinsic self-correction may not always be effective, as it has the potential to revise an initially correct response into an incorrect one
- Mechanisms for Effective Self-Correction
- When a self-correction instruction is given
- Posiive concepts in LLM will be activated
- in turn reduces model uncertainty, which decreases and stabilize the calibration error
- lead to converged self-correction performance with stable improvement
- Skill recognition explanation: multiple-round instructions locate the desired skill
- When a self-correction instruction is given
- Remaining Challenges: While skill recognition helps align LLM responses with calibrated abilities, it primarily taps into the model’s existing, pre-trained skills. Due to the inherent limitations of these capabilities, the improvements often remain superficial:
- Incomplete Correction: Self-correction struggles to fully eliminate undesirable content embedded in intermediate hidden states.
- Superficial Modification: LLMs typically add non-toxic text to the original response instead of genuinely revising problematic parts.

[1] Intrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis, Guanliang Liu, Haitao Mao et al., EMNLP 2024
[2] On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept, Haitao Mao et al., 2024