
Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs

论文网址:
https://arxiv.org/abs/2307.03393
代码地址:https://github.com/CurryTang/Graph-LLM
图是一种非常重要的结构化数据,具有广阔的应用场景。在现实世界中,图的节点往往与某些文本形式的属性相关联。以电商场景下的商品图(OGBN-Products数据集)为例,每个节点代表了电商网站上的商品,而商品的介绍可以作为节点的对应属性。在图学习领域,相关工作常把这一类以文本作为节点属性的图称为文本属性图(Text-Attributed Graph, 以下简称为TAG)。TAG在图机器学习的研究中是非常常见的, 比如图学习中最常用的几个论文引用相关的数据集都属于TAG。除了图本身的结构信息以外,节点对应的文本属性也提供了重要的文本信息,因此需要同时兼顾图的结构信息、文本信息以及两者之间的相互关系。然而,在以往的研究过程中,大家往往会忽视文本信息的重要性。举例来说,像PYG与DGL这类常用库中提供的常用数据集(比如最经典的Cora数据集),都并不提供原始的文本属性,而只是提供了嵌入形式的词袋特征。在研究过程中,目前常用的 GNN 更多关注于对图的拓扑结构的建模,缺少了对节点属性的理解。
相比于之前的工作,本文主要研究如何更好地处理文本信息,以及不同的文本嵌入与GNN结合后如何影响下游任务的性能。要更好地处理文本信息,那目前最流行的工具便非大语言模型(LLM)莫属(本文考虑了BERT到GPT4这些在大规模语料上进行了预训练的语言模型,因此使用LLM来泛指这些模型)。相比于TF-IDF这类基于词袋模型的文本特征,LLM有以下这几点潜在的优势。
- 首先,LLM具有上下文感知的能力,可以更好地处理同形不同意的单词(polysemous)。
- 其次,通过在大规模语料上的预训练,LLM一般被认为有更强的语义理解能力,这点可以从其在各类NLP任务上卓越的性能体现出来。
考虑到LLM的多种多样性,本文的目标是针对不同种类的LLM设计出合适的框架。鉴于LLM与GNN的融合问题,本文把LLM首先分类为了嵌入可见与嵌入不可见两类。像ChatGPT这类只能通过接口进行交互的LLM就属于后者。其次,针对嵌入可见类的LLM,本文考虑三种范式:
- 以BERT为代表的基于encoder-decoder结构的预训练语言模型。这类模型一般需要在下游数据进行微调。
- 以Sentence-BERT为代表的句子嵌入模型,这类模型一般在第一类模型的基础上进行了进一步的有监督/无监督训练,不需要针对下游数据进行微调。本文也考虑了以Openai的text-ada-embedding为代表的商业嵌入模型。
- 以LLaMA为代表的开源decoder-only大模型,这类模型一般会比第一类模型有大得多的参数量。考虑到微调的成本与灾难性遗忘的存在,本文主要评测了未经微调的底座模型。
对于这些嵌入可见的大模型,可以首先用它们来生成文本嵌入,然后将文本嵌入作为GNN的初始特征从而将两类模型融合在一起。然而,对于嵌入不可见的ChatGPT等LLM,如何将它们强大的能力应用于图学习相关的任务便成为了一个挑战。
针对这些问题,本文提出了一种将LLM应用到图学习相关任务的框架,如下图1与图2所示。对于第一种模式LLMs-as-Enhancers,主要是利用大模型的能力对原有的节点属性进行增强,然后再输入到GNN模型之中来提升下游任务的性能。针对嵌入可见的LLM,采取特征级别的增强,然后采用层级或迭代式(GLEM, ICLR 2023)的优化方法将语言模型与GNN结合起来。对于嵌入不可见的LLM,采取文本级别的增强,通过LLM对原有的节点属性进行扩充。考虑到以ChatGPT为代表的LLM的零样本学习与推理能力,本文进一步探索了利用prompt的形式来表示图节点的属性与结构,然后利用大模型直接生成预测的模式,将这种范式称为LLMs-as-Predictors。在实验部分,本文主要采用了节点分类这一任务作为研究对象,我们会在最后讨论这一选择的局限性,以及拓展到别的任务上的可能。接下来,顺延着论文中的结构,在这里简要分享一下各种模式下有趣的发现。


利用LLM进行特征增强:LLMs-as-Enhancers
首先,本文研究利用LLM生成文本嵌入,然后输入到GNN中的模式。在这一模式下,根据LLM是否嵌入可见,提出了特征级别的增强与文本级别的增强。针对特征级别的增强,进一步考虑了语言模型与GNN之间的优化过程,将其进一步细分为了级联式结构(cascading structure)与迭代式结构(iterative structure)。下面分别介绍两种增强方法。
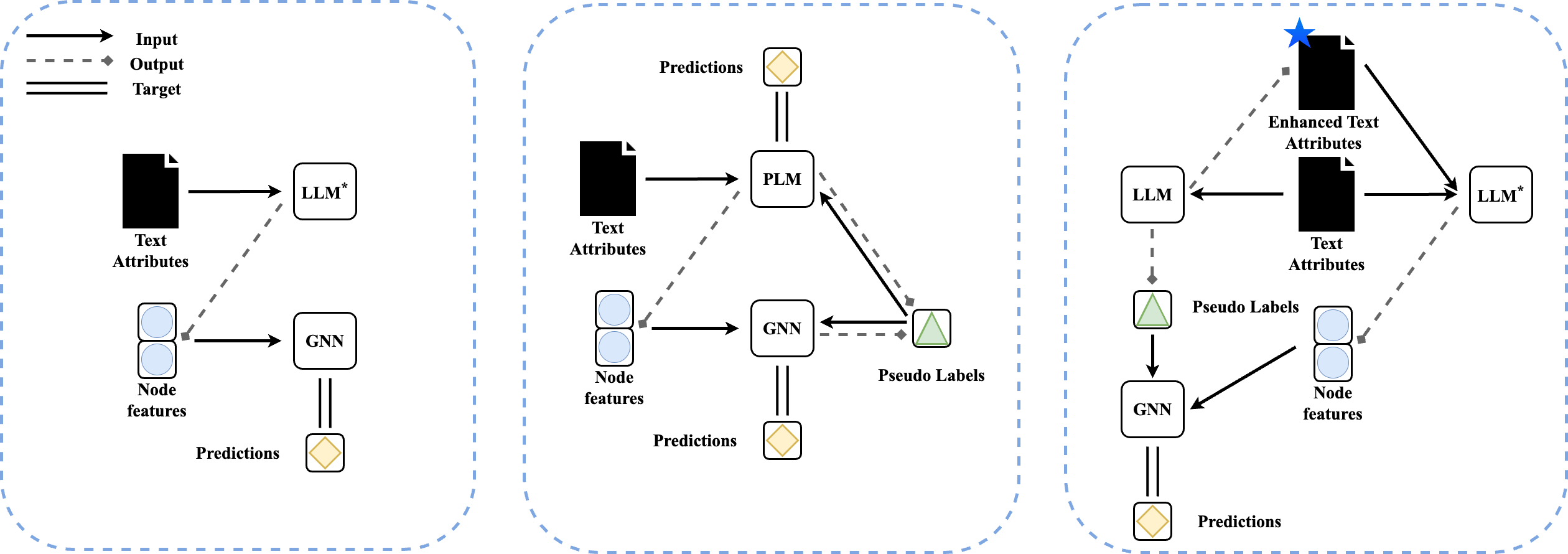
特征级别的增强
对于特征级别的增强,本文考虑的主要是语言模型、GNN、以及优化方法三个因素。从语言模型上来说,本文考虑了以Deberta为代表的预训练语言模型、以Sentence-BERT为代表的开源句子嵌入模型、以text-ada-embedding-002为代表的商业嵌入模型,以及以LLaMA为代表的开源大模型。 对于这些语言模型,本文主要从模型的种类以及模型的参数规模来考量其对下游任务的影响。
从GNN的角度来说,本文主要考虑GNN设计中的消息传递机制对下游任务的影响。本文主要选取了GCN,SAGE与GAT这两个比较有代表性的模型,针对OGB上的数据集,本文选取了目前排行榜上名列前茅的模型RevGAT与SAGN。本文也纳入了MLP对应的性能来考察原始嵌入的下游任务性能。
从优化方法的角度,本文主要考察了级联式结构与迭代式结构。对于级联式结构,本文考虑直接通过语言模型输出文本嵌入。对于那些规模较小可以进行微调的模型,本文考虑了基于文本的微调与基于结构的自监督训练(ICLR 2022, GIANT)。 不管是哪种方式,最后会得到一个语言模型,然后利用它来生成文本嵌入。这一过程中,语言模型与GNN的训练是分开的。对于迭代式结构,本文主要考察GLEM方法(ICLR 2023),它使用EM和变分推断来对GNN和语言模型进行迭代式的共同训练。
在实验部分,本文选取了几个有代表性的常用TAG数据集,具体的实验设定可以参考我们的论文。 接下来,首先展示这一部分的实验结果(鉴于空间有限,在这里展示了两个大图上的实验结果),然后简要讨论一些有意思的实验结果。
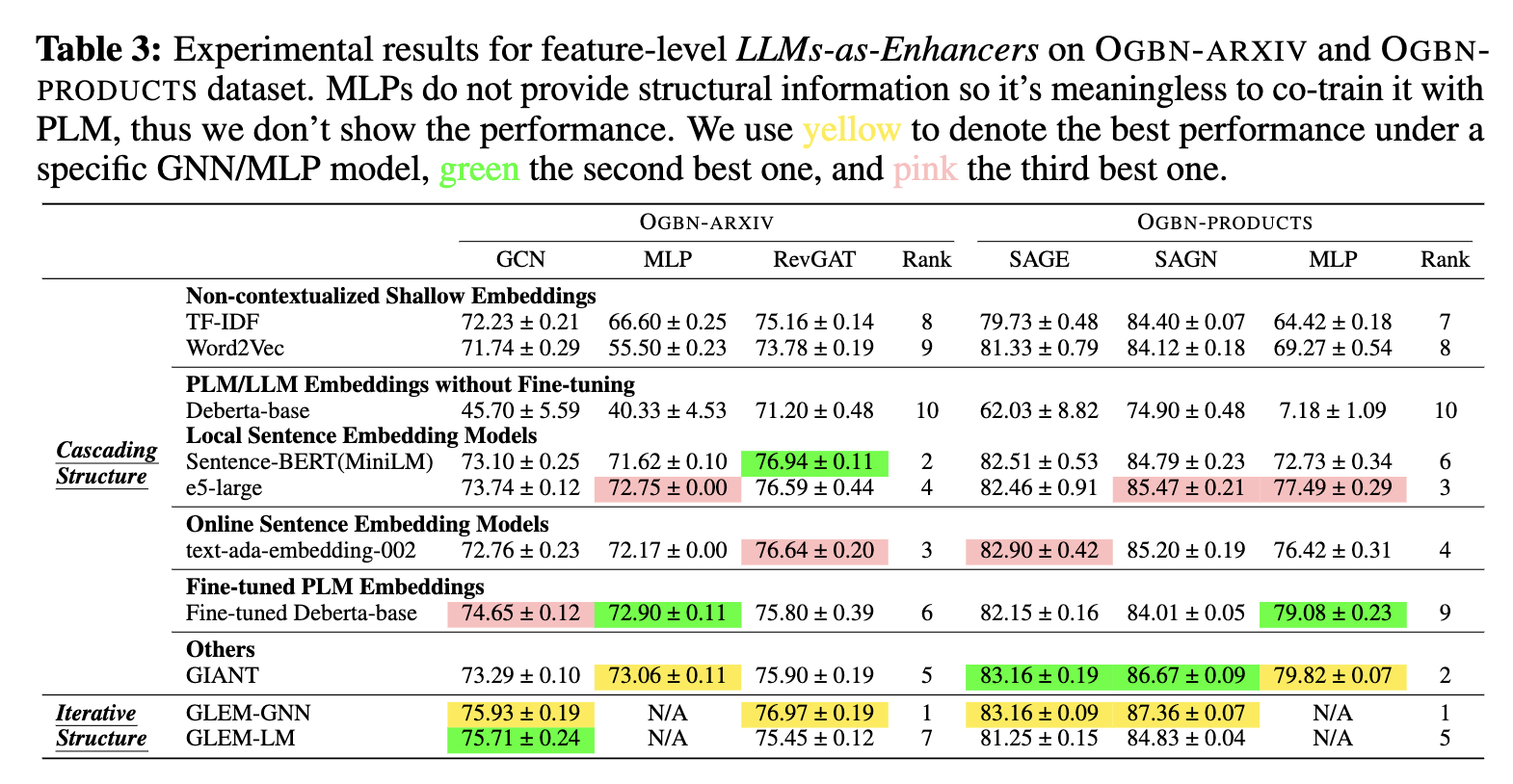
从实验结果来看,有以下几个有意思的结论。
第一,GNN对不同的文本嵌入有截然不同的有效性。特别明显的一个例子发生在Products数据集上,以MLP作为分类器时,经过微调的预训练语言模型Deberta-base的嵌入要比TF-IDF的结果好很多。然而,当使用GNN模型后,两者的差异很小,特别是使用SAGN模型时TF-IDF的表现要更好。这一现象可能与GNN的过光滑、过相关性有关,但目前还没有比较完整的解释,因此也是一个有意思的研究课题。
第二,使用句子向量模型作为编码器,然后与GNN级联起来,可以获得很好的下游任务性能。特别是在Arxiv这个数据集上,简单将Sentence-BERT与RevGAT级联起来,就可以达到接近GLEM的性能,甚至超过了做了自监督训练的GIANT。注意,这并不是因为用了一个参数量更大的语言模型,这里使用的Sentence-BERT为MiniLM版本,甚至比GIANT使用的BERT参数量更小。这里可能的一个原因是基于Natural Language Inference(NLI)这个任务训练的Sentence-BERT提供了隐式的结构信息,从形式上来说NLI与link prediction的形式也有一些相似。当然,这还只是非常初步的猜想,具体的结论还需要进一步探究。另外,从这一结果也给了一些启发,比如考虑图上的预训练模型时,能不能直接预训练一个语言模型,通过语言模型预训练更加成熟的解决方案,是不是还可以获得比预训练GNN更好的效果。同时,OpenAI提供的收费嵌入模型在节点分类这个任务上相比开源模型的提升很小。
第三,相比于未经微调的Deberta,LLaMA能够取得更好的结果,但是与句子嵌入这一类的模型还是有不小的差距。这说明相比于模型的参数大小,可能模型的种类是更重要的考量。对于Deberta,本文采用的是[CLS]作为句子向量。对于LLaMA,本文使用了langchain中的llama-cpp-embedding,它的实现中采用了[EOS]作为句子向量。在之前的相关研究中,已经有一些工作说明了为什么[CLS]在未经微调时性能很差,主要是由于其本身的各项异性,导致很差的可分性。经过实验,在高样本率的情况下,LLaMA生成的文本嵌入可以取得不错的下游任务性能,从侧面说明了模型的参数量增大可能可以一定程度上缓解这一问题。
文本级别的增强
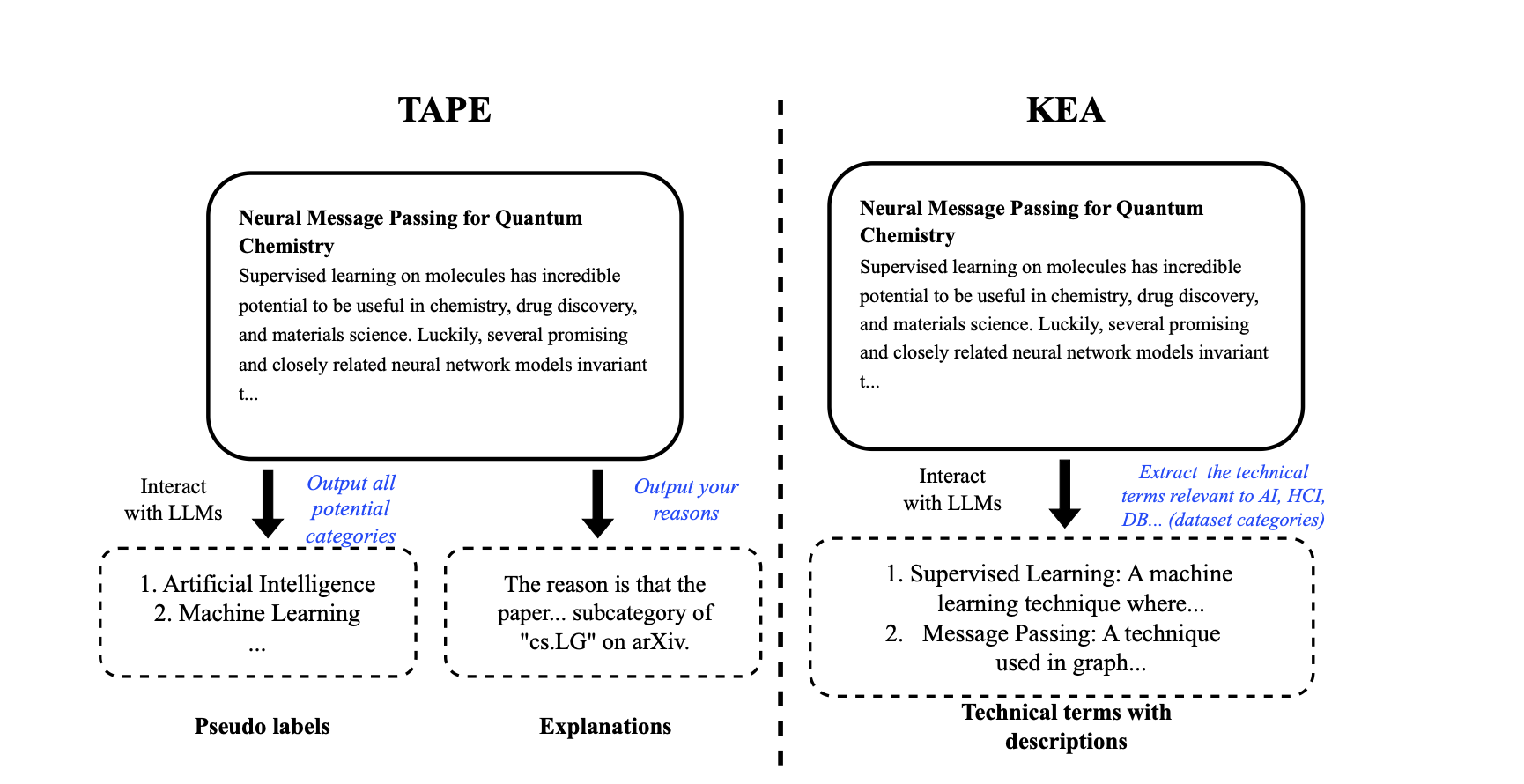
对于特征级别的增强,本文得到了一些有意思的结果。但是,特征级别的增强还是需要语言模型是嵌入可见的。对于ChatGPT这类嵌入不可见的模型,可以使用文本级别的增强。对于这一部分,本文首先研究了一篇最近挂在Arxiv上的文章Explanation as features(TAPE),其思想是利用LLM生成的对于预测的解释作为增强的属性,并通过集成的方法在OGB Arxiv的榜单上排到了第一名的位置。另外,本文也提出了一种利用LLM进行知识增强的手段Knowledge-Enhanced Augmentation(KEA),其核心思想是把LLM作为知识库,发掘出文本中与知识相关的关键信息,然后生成更为详尽的解释,主要是为了不足参数量较小的语言模型本身知识信息的不足。两种模型的示意图如下所示。


为了测试两种方法的有效性,本文沿用了第一部分的实验设定。同时,考虑到使用LLM的成本,本文在Cora与Pubmed两个小图上进行了实验。对于LLM,我们选用了gpt-3.5-turbo,也就是大家所熟知的ChatGPT。首先,为了更好地理解如何进行文本级别的增强以及TAPE的有效性,我们针对TAPE进行了详细的消融实验。
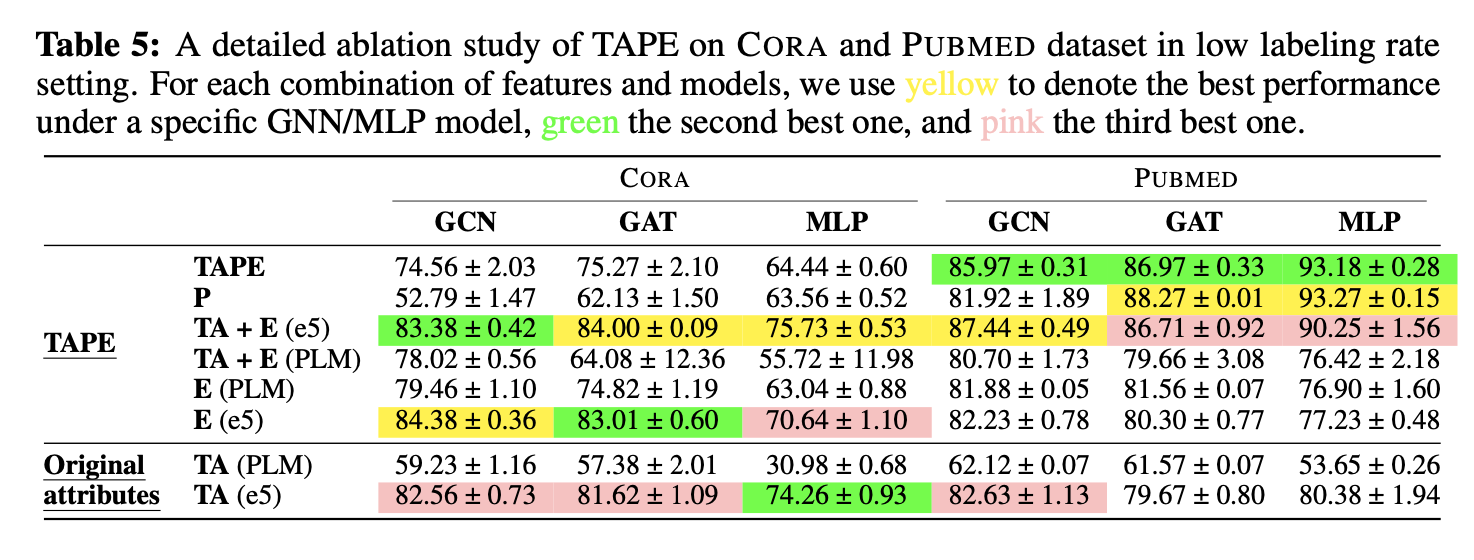
在消融实验中,我们主要考虑了以下几个问题
- TAPE的有效性主要来源于生成的解释E还是伪标签P
- 用哪种语言模型来编码增强的属性是最合适的
从实验结果可以看到,伪标签非常依赖于LLM本身的zero shot预测能力(会在下一章详细讨论),在低样本率时,可能反而会拖累集成后的性能。因此,在后续的实验中,本文只使用原始属性TA与解释E。其次,句子编码相比于微调预训练模型,可以在低标注率下取得更好的效果,因此本文采用句子编码模型e5。除此以外,一个有趣的现象是在Pubmed数据集上,当使用了增强后的特征,基于微调的方法可以取得非常好的性能。一种可能的解释是模型主要是学到了LLM预测结果的“捷径”(shortcut),因此TAPE的性能会与LLM本身的预测准确率高度相关。接下来,我们比较TAPE与KEA之间的有效性。
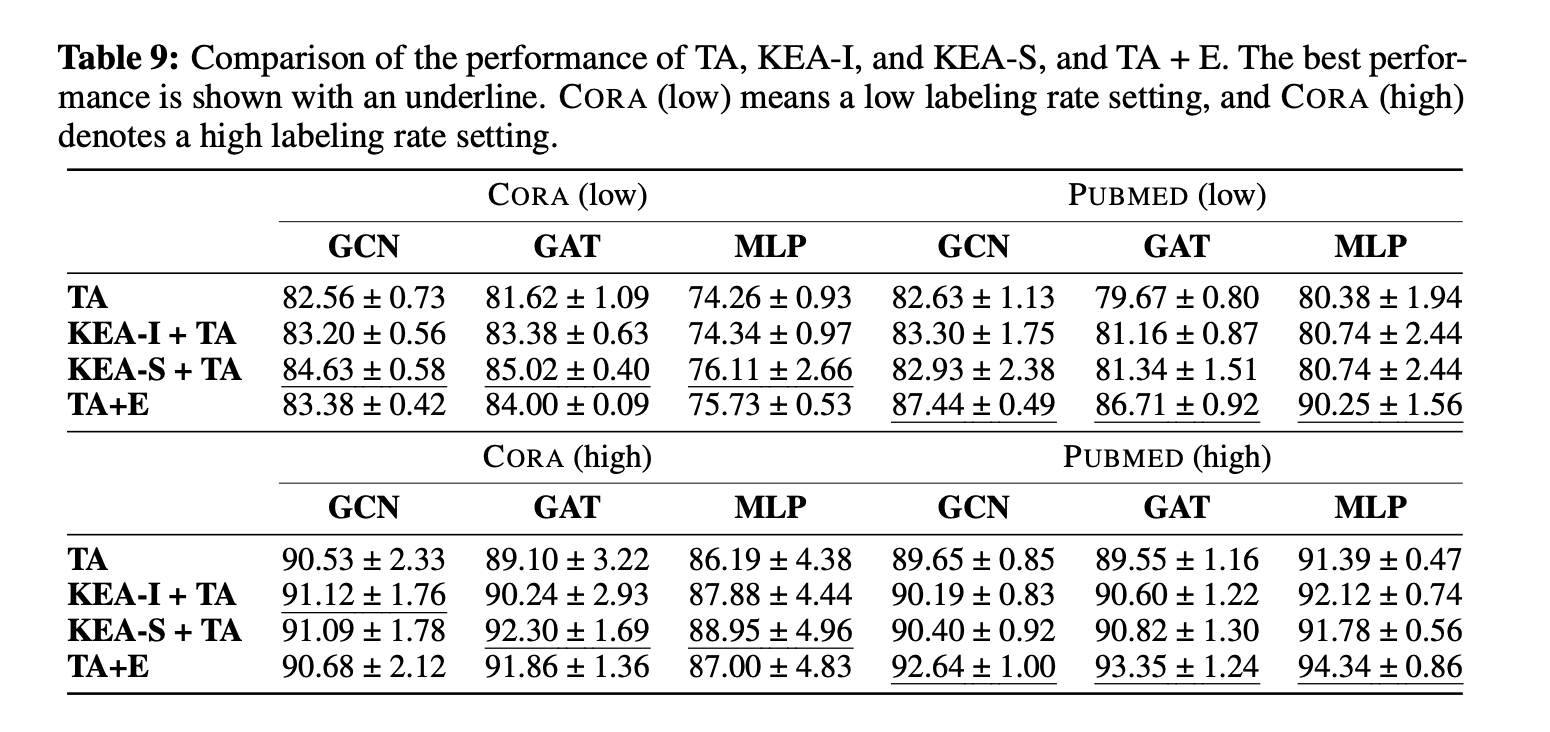
实验结果中,KEA与TAPE相比原始特征都有一定的提升。其中,KEA在Cora上可以取得更好的效果,而TAPE在Pubmed上更为有效。经过下一章的讨论后,会发现这与LLM在Pubmed上本身就有良好的预测性能有关。相比于TAPE,由于KEA不依赖LLM的预测,所以在不同数据集上的表现会更稳定一些。超越这两个数据集之外,这种文本级别的增强还有更多的应用场景。像BERT或者T5这一类比较小的预训练语言模型,往往不具备ChatGPT级别的推理能力,同时也没有办法像ChatGPT那样对不同领域的诸如代码、格式化文本有良好的理解能力。因此,在涉及到这些场景的问题时,可以通过ChatGPT这类大模型对原有的内容进行转换。在转换过后的数据上训练一个较小的模型可以有更快的推理速度与更低的推理成本。同时,如果本身也有一定量的标注样本,通过微调的方式会比上下文学习更好地掌握数据集中的一些个性化信息。
利用LLM进行预测: LLMs-as-Predictors
在这一部分,本文进一步考虑能否抛弃GNN,通过设计prompt来让LLM生成有效的预测。由于本文主要考虑的是节点分类任务,因此一个简单的基线是把节点分类看作是文本分类任务来处理。基于这个想法,本文首先设计了一些简单的prompt来测试LLM在不使用任何图结构的情况下能有多少性能。 本文主要考虑了zero shot, few shot,并且测试了使用思维链Chain of thought的效果。
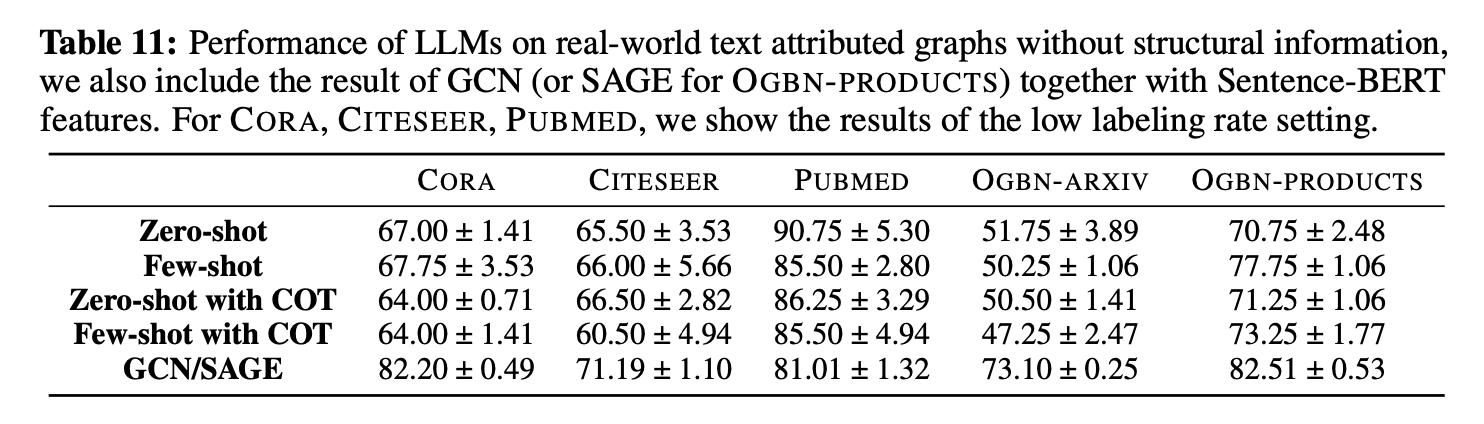
实验结果如下图所示。LLM在不同的数据集上的性能差异非常大。在Pubmed数据集上,可以看到LLM在zero shot情况下的性能甚至超过了GNN。而在Cora,Arxiv等数据集上,又与GNN有较大的差距。注意,对于这里的GNN,在Cora,CiteSeer,Pubmed上,每一类有20个样本被选为训练集,而Arxiv与Products数据集上有更多的训练样本。相比之下,LLM的预测是基于零样本或者少样本的,而GNN并不具备零样本学习的能力,在少样本的情况下性能也会很差。当然,输入长度的限制也使得LLM无法囊括更多的上下文样本。
通过对实验结果进行分析,在某些情况下LLM预测错的结果也是比较合理的。一个例子如图12所示。可以看到,很多论文本身也是交叉领域的,因此预测时LLM通过自身的常识性信息进行推理,有时并不能与标注的偏好匹配到一起。这也是值得思考的问题:这种单标签的设定是合理的吗?

此外,在Arxiv数据集上LLM的表现最差,这与TAPE中的结论并不一致,因此需要比较一下两者的prompt有什么差异。TAPE使用的prompt如下所示。
Abstract: <abstract text> \n Title: <title text> \n Question: Which arXiv CS sub-categorydoes this paper belong to? Give 5 likely arXiv CS sub-categories as a comma-separated list ordered from most to least likely, in the form “cs.XX”, and provide your reasoning. \n \n Answer:
有意思的是,TAPE甚至都没有在prompt中指明数据集中存在哪些类别,而是直接利用了LLM中存在的关于arxiv的知识信息。奇怪的是,通过这个小变化,LLM预测的性能有巨大的改变,这不禁让人怀疑与本身测试集标签泄漏有关。作为高质量的语料,arxiv上的数据大概率是被包含在了各种LLM的预训练之中,而TAPE的prompt可能使得LLM可以更好地回忆起这些预训练语料。这提醒我们需要重新思考评估的合理性,因为这时的准确率可能反映的并不是prompt的好坏与语言模型的能力,而仅仅只是LLM的记忆问题。以上两个问题都与数据集的评估有关,是非常有价值的未来方向。
进一步地,本文也考虑了能否在prompt中通过文本的形式把结构信息也包含进来。本文测试了几种方式来在prompt中表示结构化的信息。具体地,我们尝试了使用自然语言“连接”来表示边关系以及通过总结周围邻居节点的信息来隐式表达边关系。
结果表明,以下这种隐式表达的方式最为有效。
Paper:<paper content>
NeighborSummary:<Neighborsummary>
Instruction:<Task instruction>
具体来说,模仿GNN的思路,对二阶邻居节点进行采样,然后将对应的文本内容输入到LLM中,让其进行一个总结,作为结构相关信息,一个样例如图13所示。

本文在几个数据集上测试了prompt的有效性,结果如图14所示。在除了Pubmed以外的其他四个数据集上,都可以相对不考虑结构的情况获得一定的提升,反映了方法的有效性。进一步地,本文分析了这个prompt为什么在Pubmed数据集上失效。

在Pubmed数据集上,很多情况下样本的标注会直接出现在样本的文本属性中。一个例子如下所示。由于这个特性的存在,想要在Pubmed数据集上取得比较好的结果,可以通过学习到这种“捷径”,而LLM在此数据集上特别好的表现可能也正源于此。在这种情况下,如果加上总结后的邻居信息,可能反而会使得LLM更难捕捉到这种“捷径”信息,因此性能会下降。
Title: Predictive power of sequential measures of albuminuria for progression to ESRD or death in Pima Indians with type 2 diabetes. … (content omitted here)
Ground truth label: Diabetes Mellitus Type 2
进一步地,在一些邻居与本身标签不同的异配(heterophilous)点上,LLM同GNN一样会受到邻居信息的干扰,从而输出错误的预测。

GNN的异配性也是一个很有意思的研究方向,大家也可以参考我们的论文Demystifying Structural Disparity in Graph Neural Networks: Can One Size Fit All?
案例研究:利用LLM生成标注
从上文的讨论中可以看到,在一些情况下LLM可以取得良好的零样本预测性能,这使得它有代替人工为样本生成标注的潜力。本文初步探索了利用LLM生成标注,然后用这些标注训练GNN的可能性。
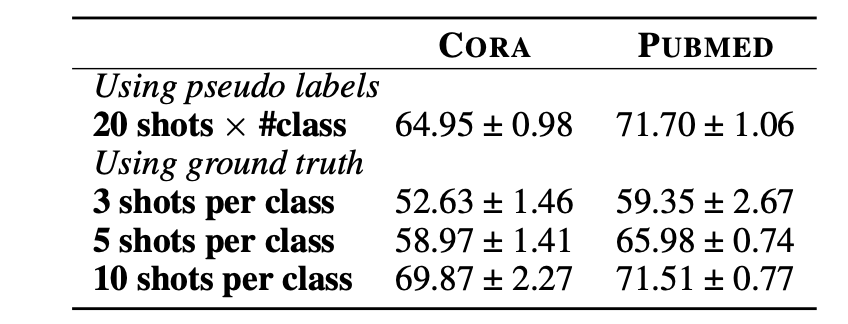
针对这一问题,有两个需要研究的点
- 如何根据图结构和属性选择图中重要的点,来使得标注的收益最大化,这与图上主动学习的设定类似
- 如果估计LLM生成的标注质量,并且过滤错误的标注
讨论
最后,简要讨论一下本文的局限性,以及一些有意思的后续方向。首先,需要说明的是本文主要针对的还是节点分类这个任务,而这个pipeline要扩展到更多的图学习任务上还需要更多的研究,从这个角度来说标题或许也有一些overclaim。另外,也有一些场景下无法获取有效的节点属性。比如,金融交易网络中,很多情况下用户节点是匿名的,这时如何构造能够让LLM理解的有意义的prompt就成为了新的挑战。
其次,如何降低LLM的使用成本也是一个值得考虑的问题。在文中,讨论了利用LLM进行增强,而这种增强需要使用每个节点作为输入,如果有N个节点,那就需要与LLM有N次交互,有很高的使用成本。在实验过程中,我们也尝试了像Vicuna这类开源的模型,但是生成的内容质量相比ChatGPT还是相去甚远。另外,基于API对ChatGPT进行调用目前也无法批处理化,所以效率也很低。如何在保证性能的情况下降低成本并提升效率,也是值得思考的问题。
最后,一个重要的问题就是LLM的评估。在文中,已经讨论了可能存在的测试集泄漏问题以及单标注设定不合理的问题。要解决第一个问题,一个简单的想法是使用不在大模型预训练语料范围内的数据,但这也需要我们不断地更新数据集并且生成正确的人工标注。对于第二个问题,一个可能的解决办法是使用多标签(multi label)的设定。对于类似arxiv的论文分类数据集,可以通过arxiv本身的类别生成高质量的多标签标注,但对更一般的情况,如何生成正确的标注还是一个难以解决的问题。
参考文献
[1] Zhao J, Qu M, Li C, et al. Learning on large-scale text-attributed graphs via variational inference[J]. arXiv preprint arXiv:2210.14709, 2022.
[2] Chien E, Chang W C, Hsieh C J, et al. Node feature extraction by self-supervised multi-scale neighborhood prediction[J]. arXiv preprint arXiv:2111.00064, 2021.
[3] He X, Bresson X, Laurent T, et al. Explanations as Features: LLM-Based Features for Text-Attributed Graphs[J]. arXiv preprint arXiv:2305.19523, 2023.